01编译原理概述
教学相关
- 内容:介绍高级程序设计语言的编译程序,包括基本架构,设计原理与方法,主要实现方法和相关自动构造工具
- 最后要求:掌握编译器的基本结构和工作机制,能独立完成小型编译器
- 参考书:龙书《编译原理》
- 评分标准:平时20% 实验30% 期末闭卷50%
概述
编译过程
是一个基于规则的语言翻译过程
- 词法分析
- 语法分析
- 语义分析
- 优化
词法分析
把输入的每个单词确定类型,得到统一的词法单元(token)形式
token: <种别码, 属性值>
| 单词类型 | 种别 | 种别码 | |
|---|---|---|---|
| 1 | 关键字 | int、if、else、class… | 一词一码 |
| 2 | 标识符 | 变量名、数组名、类名、函数名、… | 多词一码 |
| 3 | 常量 | 整型、浮点型、字符型、布尔型、… | 一型一码 |
| 4 | 算符 | 算术(+ - * / ++ –) 关系(> < == != >= <=) 逻辑(& | ~) |
一词一码 或 一型一码 |
| 5 | 界符 | ; ( ) , { } … | 一词一码 |
eg.
对下面的语句进行词法分析
1 | position = initial + rate * 60 ; |
| 序号 | Token(<种别码, 属性值>) | 对应原词法单元 | 说明 |
|---|---|---|---|
| 1 | <标识符, position> | position | 自定义变量名 |
| 2 | <赋值运算符, => | = | 赋值操作符号 |
| 3 | <标识符, initial> | initial | 自定义变量名 |
| 4 | <加法运算符, +> | + | 算术加法符号 |
| 5 | <标识符, rate> | rate | 自定义变量名 |
| 6 | <乘法运算符, *> | * | 算术乘法符号 |
| 7 | <整型常量, 60> | 60 | 十进制整数常量 |
| 8 | <语句结束符, ;> | ; | 语句终止的界符 |
得到
1 | <标识符, position> <赋值运算符, => <标识符, initial> <加法运算符, +> <标识符, rate> <乘法运算符, *> |
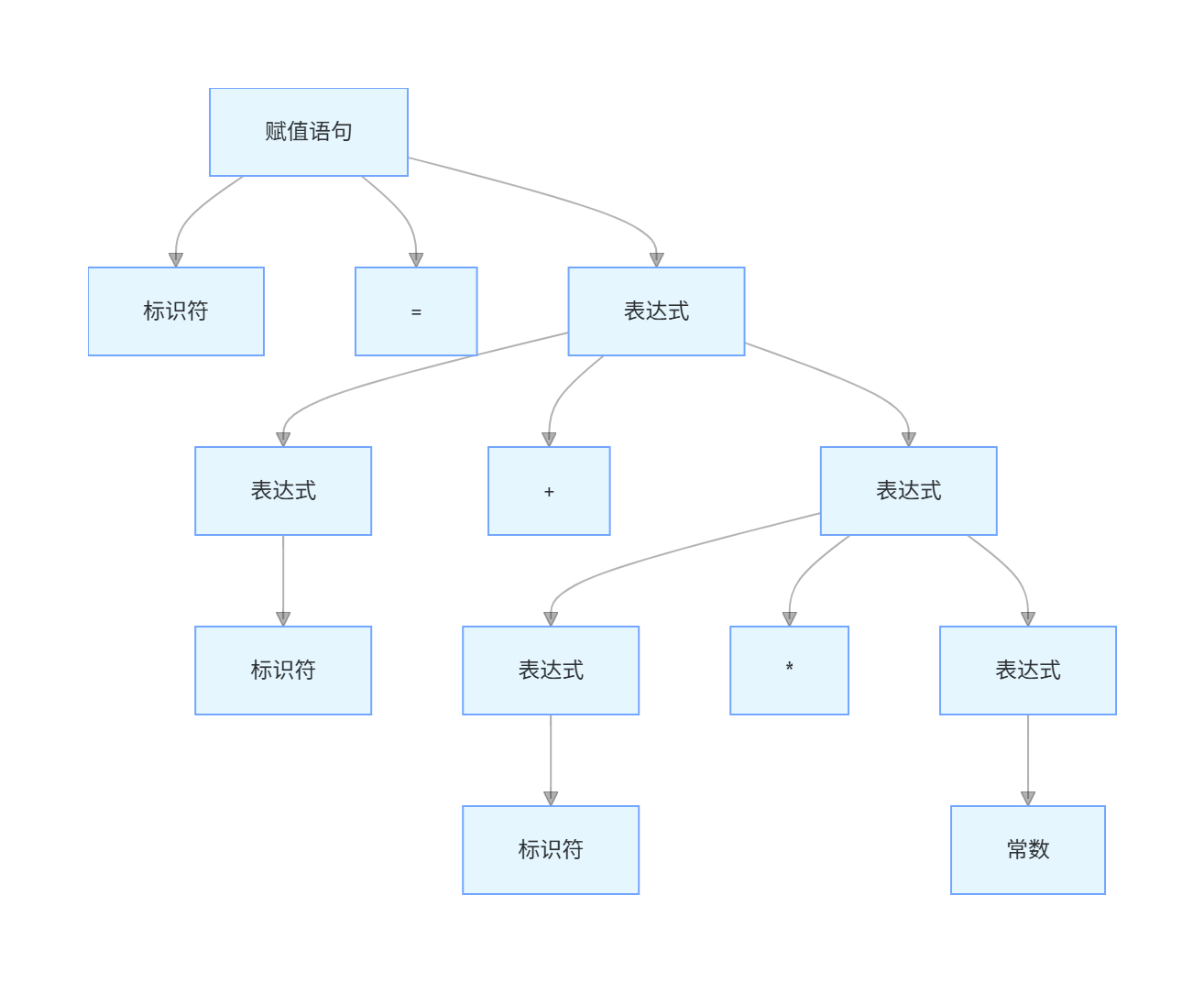
语法分析
依据语法规则,从源程序的单词符号串(词法分析器输出的token序列)识别出短语(语法分析的基本单位),短语符合的规则是先定义好的
eg.
还是对上面的语句进行语法分析
比如规则有:
<赋值语句>::=<标识符>“=”<表达式>
<表达式>::=<表达式>“+”<表达式>
<表达式>::=<表达式>“*”<表达式>
<表达式>::=<标识符>
<表达式>::=<整数>
<表达式>::=<实数>
那么可以得到一个语法树
进而可以得到抽象语法树
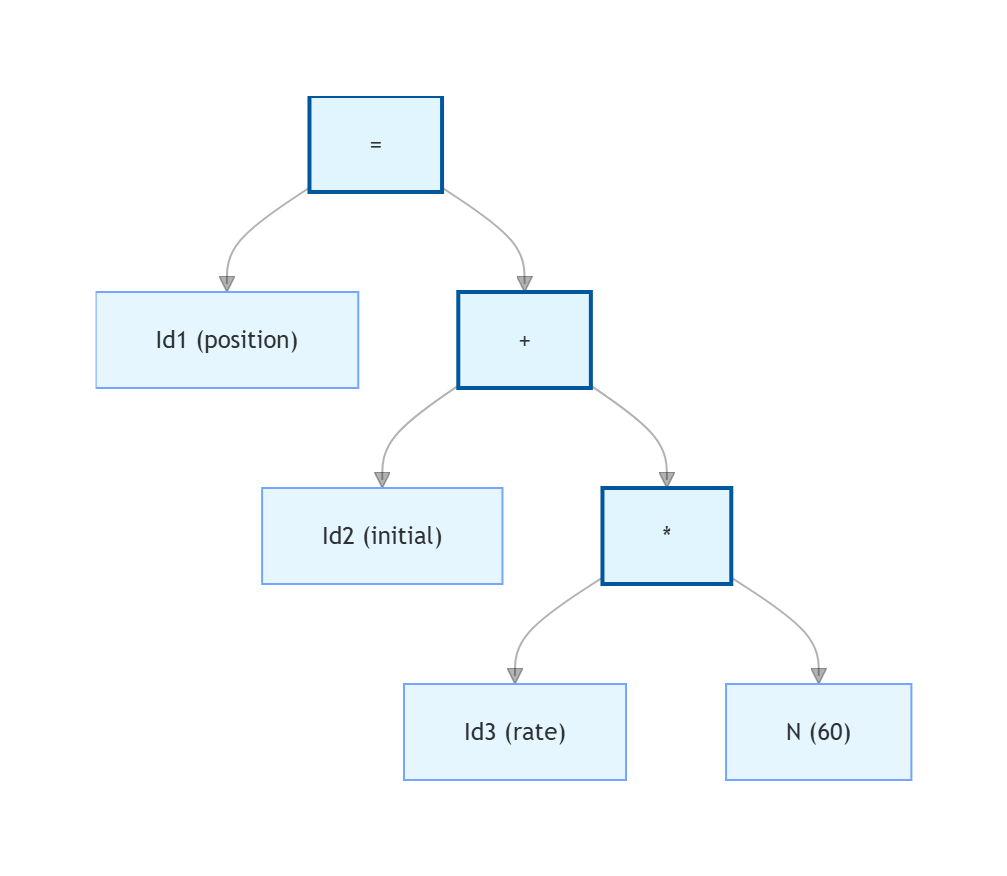
而对于
1 | position + initial = rate * 60; |
就无法得到一个符合规则的语法树,因此语法错误。
eg. 变量声明语句
对
1 | int a, b, c; |
进行分析。
文法(规则)
可以得到
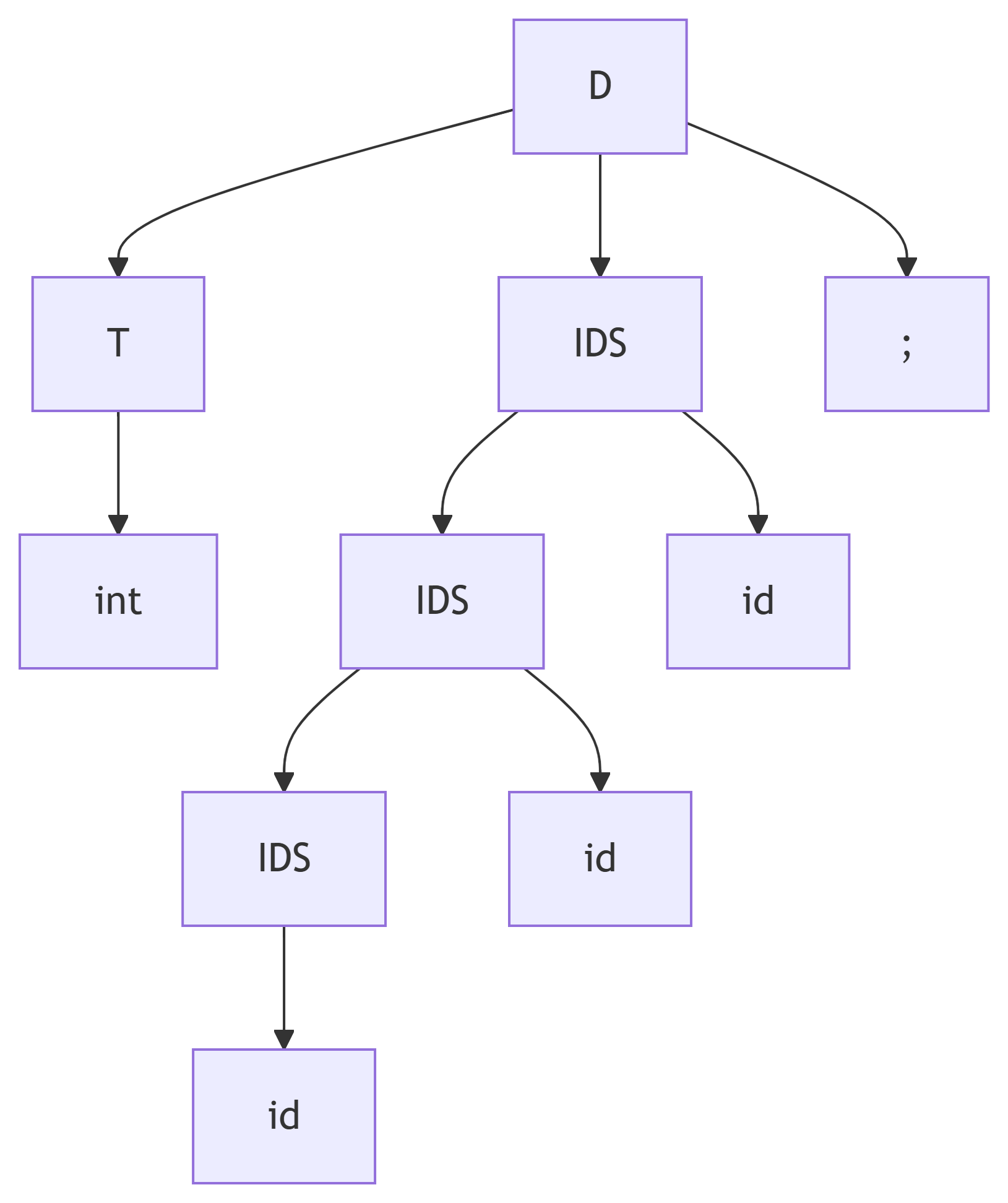
语义分析
- 收集标识符的属性信息 种属(Kind)、类型(Type)、存储位置、长度、值、作用域、参数和返回值信息、参数个数、参数类型、参数传递方式、返回值类型、…
- 语义检查
- 静态类型系统:变量或过程未经声明就使用
- 变量或过程名重复声明
- 运算分量类型不匹配
- 操作符与操作数之间的类型不匹配
- 数组下标不是整数
- 对非数组变量使用数组访问操作符
- 对非过程名使用过程调用操作符
- 过程调用的参数类型或数目不匹配
- 函数返回类型有误
还是刚刚的例子,得到另一个语法树
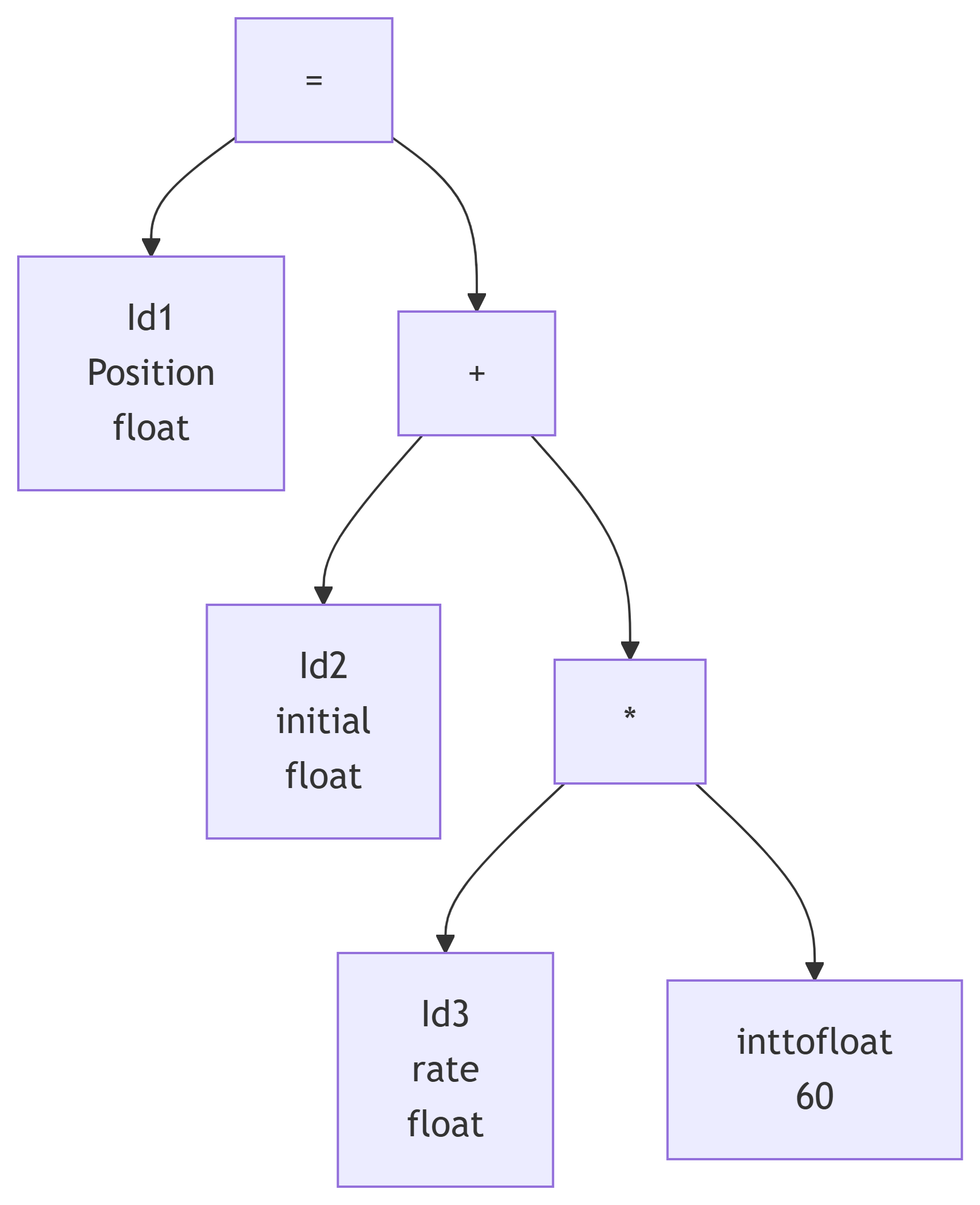
中间代码生成
中间代码:
- 独立于具体的硬件
- 与机器指令接近,易变换成机器指令
- 常见的中间代码形式:三地址代码
- 如:四元式:(算符、左操作数、右操作数、结果)
- 对左右操作数进行某种运算,所得值保存在结果中
- 按语义规则,生成四元式序列
eg.
1 | id1 = id2 + id3 * 60 |
1 | (1) (inttofloat, 60 - t1 ) |
代码优化
对中间代码加工变换,生成更高效的目标代码,让代码运行得更快一些、占用空间更少一些,或者二者兼顾。
方法是方法:公共子表达式的提取,循环优化,删除无用代码等
原则是等价变换
eg. 上面的中间代码经过优化后得到如下代码:
1 | (1) ( * id3 60.0 t1 ) |
目标代码生成
把中间代码转换为特定机器上的低级语言代码
目标代码生成的一个重要任务是为程序中使用的变量合理分配寄存器
目标代码的形式:
- 绝对指令代码
- 可重定位的指令代码
- 汇编指令代码
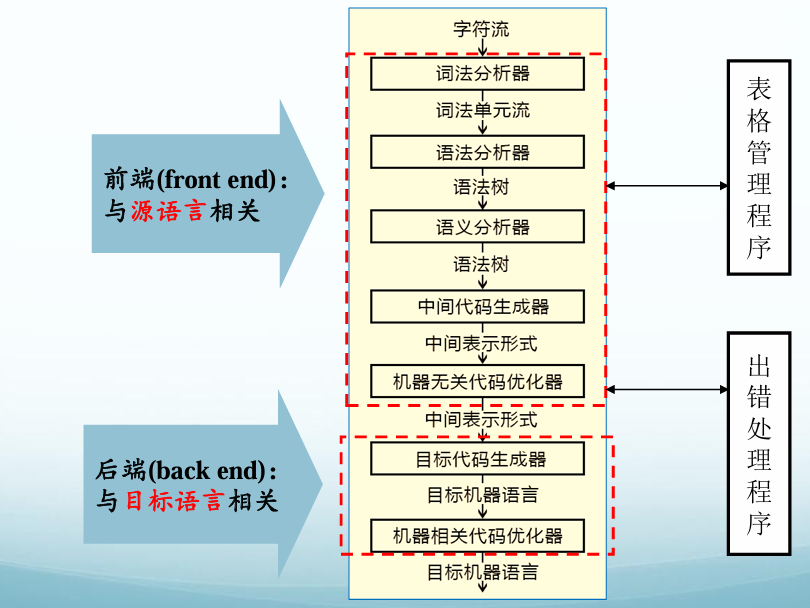
编译程序结构
- 表格管理:符号表
- 记录源程序中使用的名字
- 收集每个名字的各种属性信息
- 类型、作用域、分配的存储单元信息
- 出错管理:检查错误、报告出错信息、排错、恢复编译工作
- 错误分类
- 语法错误:非法字符,括号不匹配
- 语义错误:说明错误,作用域错误,类型不一致
- 遍(Pass):
- 对源程序或源程序的中间结果从头到尾扫描一遍
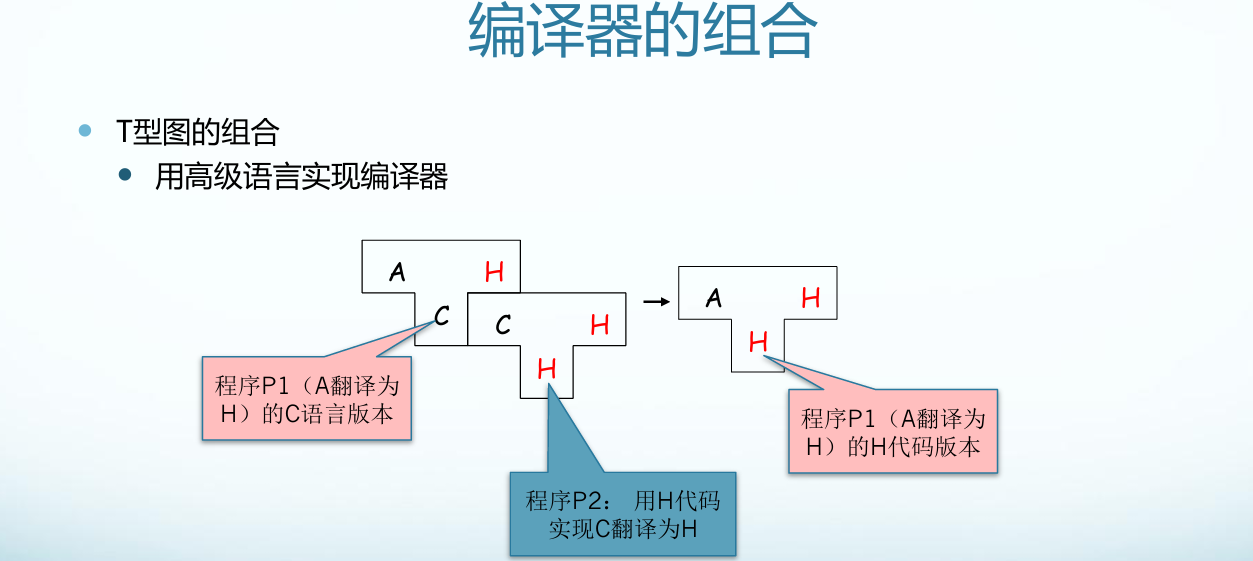
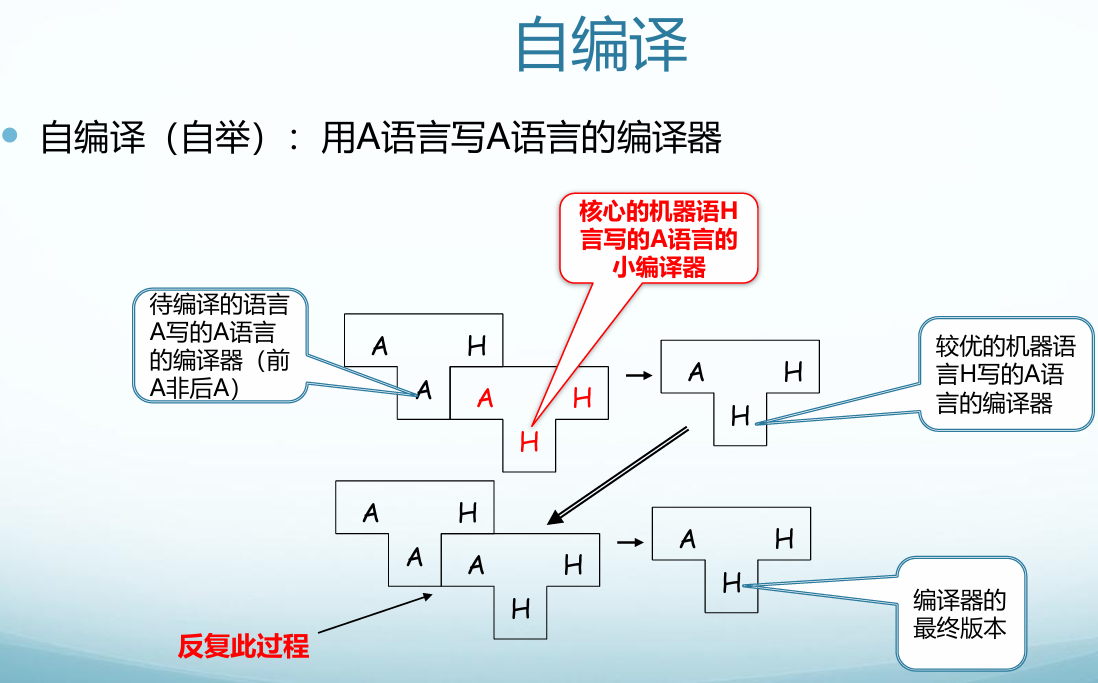
编译程序的生成
实现编译程序的语言:机器语言,汇编语言或高级语言
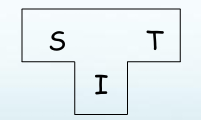
用T型图表示:S:源语言;T:目标语言;I:编译器实现语言