


《Action-Aware Embedding Enhancement for Image-Text Retrieval》总结
一、核心问题
- 现有图像-文本检索只靠物体(名词)匹配,严重忽略动作(动词)的关键作用。
- 图文动作信息不对称:文本有明确动作描述,图像只有隐含动作。
- 细粒度匹配方法精度高,但推理太慢,不实用。
二、整体思路
把动作信息显式加进图像和文本特征,解决动作不对称
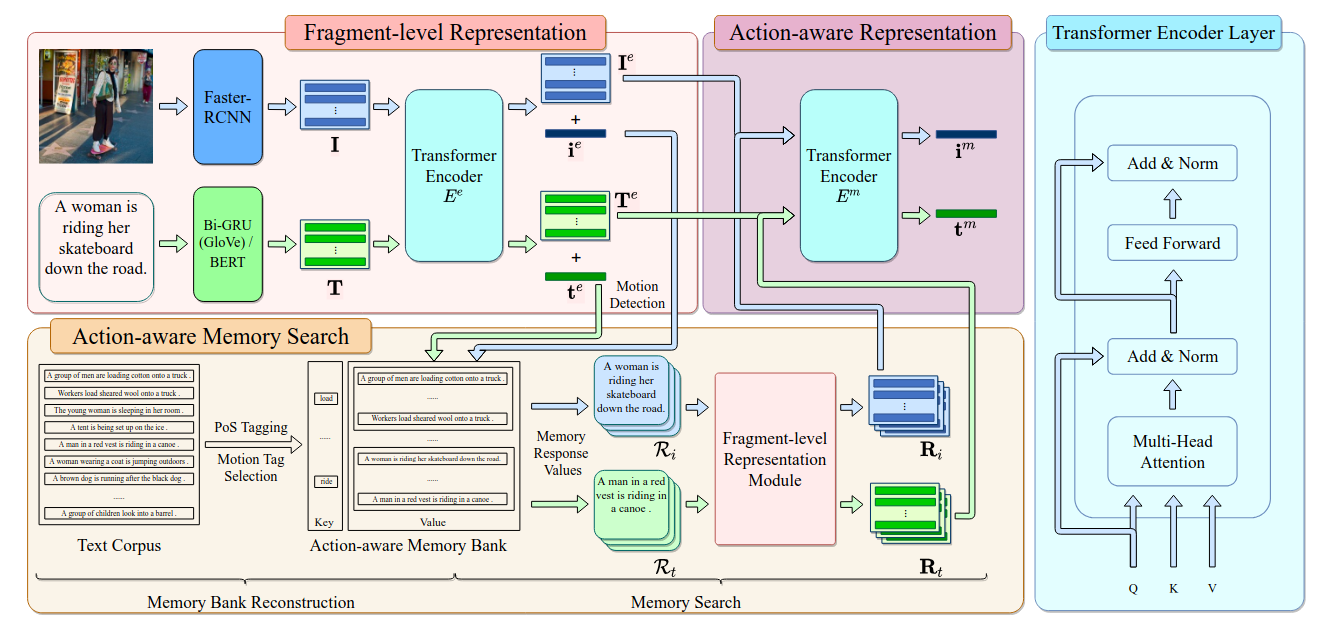
三、整体流程
1. 基础特征提取
- 图像:Faster R-CNN 提取区域特征向量 → 变成“区域序列”
- 文本:GloVe+Bi-GRU 或 BERT 提取词特征向量 → 变成“单词序列”
- 目的:让图像、文本都变成序列结构,方便统一处理
2. 共享 Transformer 编码(空间对齐)
- 图像序列、文本序列共用同一套 Transformer Encoder(权重共享)
- 输出:同一语义空间的图像区域token、文本单词token
- 作用:强制图文特征对齐,方便后续算相似度
3. 动作预测
- 对图像/文本的全局特征做预测,输出动作分数向量(每个动作对应0~1概率)
- 作用:得到图文的显式动作信息
4. 动作感知记忆库
- 结构:key=动作短语,value=对应文本的特征向量
- 用途:用预测的动作,召回动作相似文本,用来强化原图/原文特征
5. 动作感知特征融合
- 用 Transformer 把原图/原文特征 + 动作相似文本特征融合
- 输出:动作增强后的嵌入向量
6. 最终表示
- 把动作感知嵌入 + 动作预测分数直接拼接
- 得到最终向量,用于计算余弦相似度、排序检索
四、损失函数
- 三元组排序损失:让匹配图文更近,不匹配图文更远
- 二元交叉熵损失:监督动作预测,让动作分数更准
- 加权联合训练
传统图文检索 + 显式动作建模 + 动作相似文本增强 → 解决动作不对称 → 更准更快的图像-文本检索
