


这篇论文提出基于 CLIP 的轻量级 Combiner 网络,实现图像+文本修改指令的组合图像检索,在时尚(FashionIQ)与通用场景(CIRR)均达到 SOTA,模型简单、训练高效、极易落地。
1. 解决的任务
条件/组合图像检索
- 输入:参考图像 + 文本修改描述
- 输出:符合“原图+修改”的目标图像
- 典型场景:电商时尚搜索(红裙子→蓝裙子)
2. 核心创新
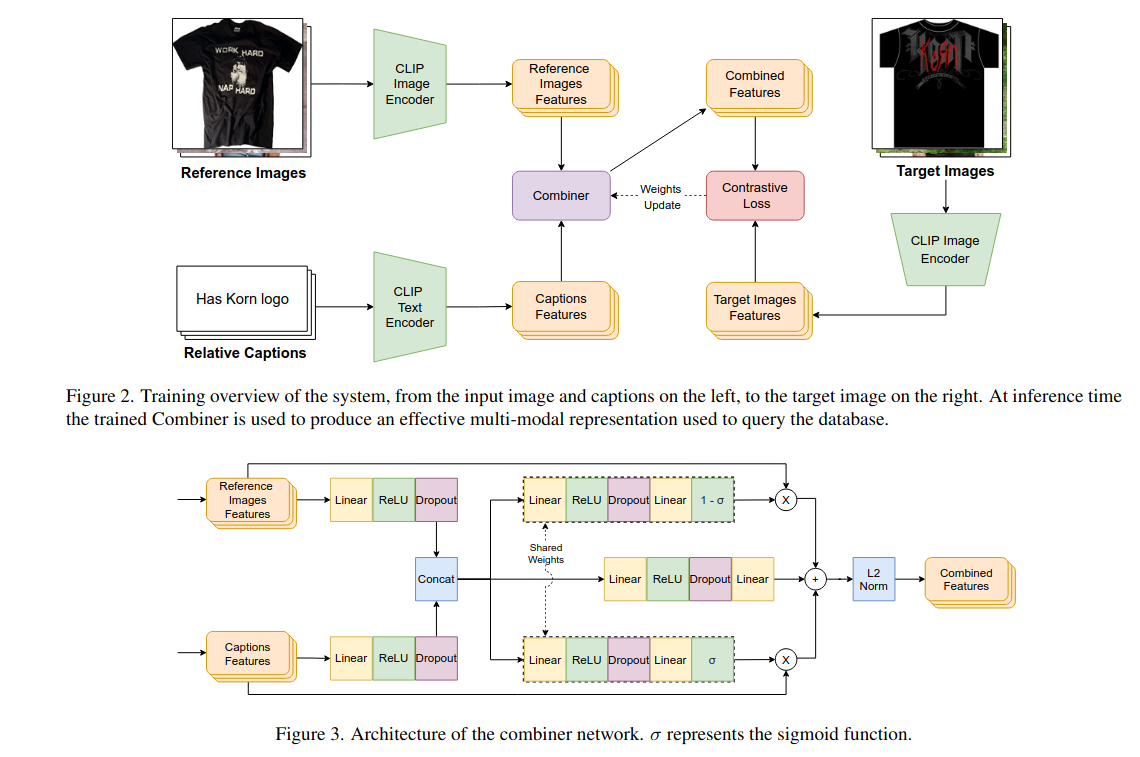
- 轻量 Combiner 融合网络
- 输入:CLIP 图像特征、CLIP 文本特征(均冻结)
- 计算:图像特征 + 文本×门控 + 图文交叉 MLP(加法式融合)
- 输出:同维度目标图预测特征(仍在 CLIP 公共空间)
- BBC 批量对比学习损失
- 用三元组(参考图、文本、目标图)训练
- 正样本:融合特征 ↔ 自身目标图特征
- 负样本:同 batch 内其他目标图特征
- 只训 Combiner,CLIP 全程不动
- 优化图像预处理
- 不直接中心裁剪,先按长宽比 1.25 补零 padding
- 保留完整图像内容,提升检索精度
3. 训练流程
- 数据:(I_ref, T_modify, I_target)
- 冻结 CLIP 提取:img_feat / txt_feat / target_feat
- 前向:img_feat + txt_feat → Combiner → query_feat
- 损失:BBC 让 query_feat 靠近 target_feat、远离其他
- 仅更新 Combiner 参数
4. 推理/应用流程
- 用户输入:参考图 + 修改文本
- 冻结 CLIP 提取图文特征
- Combiner 输出检索向量
- 在预计算 CLIP 特征图库中做最近邻搜索
- 返回最相似图像
5. 效果(SOTA)
- FashionIQ(时尚):R@10 35.39%、R@50 59.03%,大幅领先
- CIRR(通用):R@1 33.59%、Subset R@1 62.39%,细粒度极强
6. 亮点与价值
- 架构极简,无 Transformer/GNN/空间信息
- 训练成本低,仅训小网络
- 速度快:单查询 <70ms,低配置 GPU 可跑
- 落地性强:电商搜索、交互式检索、多轮对话搜索
ps.
Combiner 加法式融合公式:
$$\mathbf{f}{out} = \mathbf{f}{img} + \left( \mathbf{f}{txt} \odot \sigma\left( \text{MLP}(\mathbf{f}{img},\mathbf{f}{txt}) \right) \right) + \text{MLP}(\mathbf{f}{img},\mathbf{f}_{txt})$$
符号说明(简洁版,存文档用)
- $\mathbf{f}_{img}$:CLIP 图像特征
- $\mathbf{f}_{txt}$:CLIP 文本特征
- $\sigma$:sigmoid 门控函数(输出 0~1 权重)
- $\odot$:逐元素相乘
- $\text{MLP}(\cdot)$:轻量多层感知机(图文交叉信息)
- $\mathbf{f}_{out}$:最终融合检索特征
