


MKVSE论文详细总结:多模态知识增强的视觉-语义嵌入图像文本检索方法
一、论文基础信息
- 论文标题:MKVSE: Multimodal Knowledge Enhanced Visual-semantic Embedding for Image-text Retrieval(多模态知识增强的视觉-语义嵌入用于图像-文本检索)
- 作者:Duoduo Feng、Xiangteng He、Yuxin Peng(北京大学王选计算机研究所,彭玉鑫为通讯作者,同时隶属鹏城实验室)
- 发表信息:ACM Transactions on Multimedia Computing, Communications and Applications (TOMM),2023年3月,第19卷第5期
- DOI:10.1145/3580501
- 核心任务:图像-文本跨模态检索(文本查图像、图像查文本)
- 实验数据集:Flickr30k、MSCOCO(1k/5k测试集)
- 开源代码:https://github.com/PKU-ICST-MIPL/MKVSE-TOMM2023
- 基金支持:国家自然科学基金、2022腾讯微信犀牛鸟专项研究计划
二、研究背景与核心问题
1. 任务定义
图像-文本检索是用文本查询检索相关图像、用图像查询检索相关文本,是搜索系统、电商、社交网络的核心基础任务。
2. 现有方法缺陷
- 传统视觉-语义嵌入(VSE)仅学习图像与文本的联合嵌入空间,忽略隐式多模态知识关联;
- 部分方法仅利用单模态知识(如文本共现、场景图),无法处理图像含文本未直接描述信息的场景(例:图像有水龙头,文本仅写“清洗”);
- 现有图推理方法未显式建模跨模态隐式关系,无法充分挖掘图像与文本间的语义关联。
3. 核心痛点
当图像包含文本未直接描述的实体时,模型无法通过隐式语义关系(如“清洗-水龙头”“切菜-刀”)建立图像与文本的关联,导致检索精度不足。
三、核心创新贡献
- 提出多模态知识图谱(MKG)
显式建模图像与文本间的模态内语义关系(同义词、上下位)和模态间共现关系(时序、因果、逻辑关联),解决隐式知识缺失问题。 - 提出多模态图卷积网络(MGCN)
采用两步推理机制,分别挖掘模态内、模态间关系,充分利用MKG中的隐式知识增强特征表示。 - 多模态知识增强嵌入
结合多头注意力将MKG知识注入图像/文本全局特征,在Flickr30k、MSCOCO数据集上达到SOTA性能。
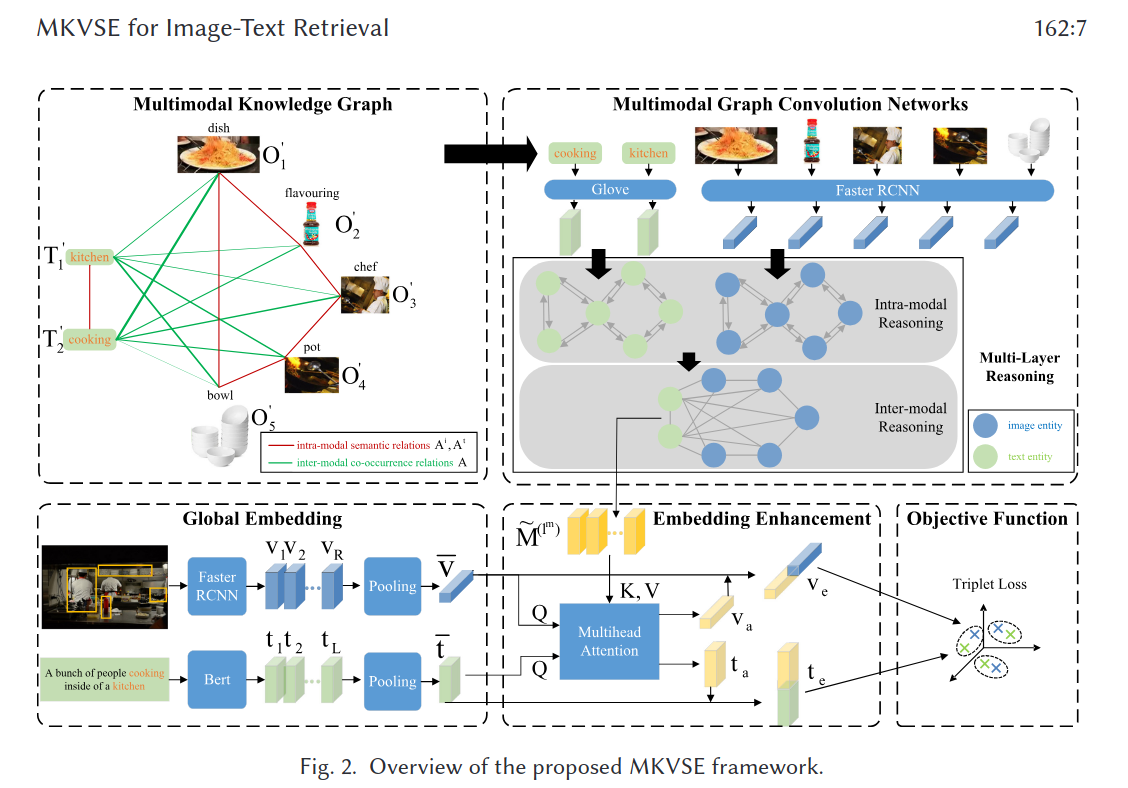
四、方法框架:MKVSE五大核心组件
MKVSE整体架构分为全局嵌入、多模态知识图谱、多模态图卷积网络、嵌入增强、目标函数五部分:
1. 全局嵌入(Global Embedding)
- 图像嵌入:用BUTD模型提取36个感兴趣区域(ROI)特征,经全连接层投影后,采用GPO泛化池化得到全局图像特征;
- 文本嵌入:用预训练BERT提取词特征,经全连接层投影后,同GPO池化得到全局文本特征。
2. 多模态知识图谱(MKG)
(1)实体构建
选取Visual Genome数据集中高频图像物体和高频文本单词作为实体,过滤无意义词汇(如is、a),最终设定图像/文本实体数均为300。
(2)关系构建
- 模态内语义关系:用WordNet路径相似度计算,区分语义不同的实体(如区分“人”和“狗”);
- 模态间共现关系:统计图像-文本对中实体的共现频率,刻画隐式关联(如“清洗-水龙头”)。
(3)实体表示
- 文本实体:GloVe预训练词向量;
- 图像实体:同类物体区域特征的均值池化。
3. 多模态图卷积网络(MGCN)
采用两步分步推理,解决多模态图特征融合问题:
- 第一步:模态内关系推理
分别对图像实体、文本实体做图卷积,学习模态内语义特征,区分不同实体; - 第二步:模态间关系推理
对完整MKG做图卷积,融合跨模态共现特征,建立图像与文本的隐式关联。
4. 嵌入增强(Embedding Enhancement)
用多头注意力机制,将MGCN学习到的MKG实体特征注入图像/文本全局特征,生成知识增强的跨模态嵌入,兼顾原始特征与知识特征。
5. 目标函数
采用双向铰链损失(基于难负样本挖掘),优化图像-文本正对的相似度,拉开负对相似度,实现跨模态嵌入对齐。
五、实验验证与结果分析
1. 实验设置
- 评估指标:R@1/R@5/R@10(前K个结果命中真值的比例)、RSUM(所有R@K求和);
- 骨干网络:BUTD图像编码器 + BERT文本编码器;
- 超参数:MGCN层数1层、知识融合权重λc=0.05、批量大小128。
2. 对比实验(SOTA验证)
- 单模型:MGCN在Flickr30k、MSCOCO上的R@1指标超越所有现有单模型,RSUM相对提升最高7.6%;
- 融合模型(MKVSE):在三大测试集上*全面超越所有SOTA方法,Flickr30k图像查文本R@1达84.0%,文本查图像R@1达64.4%;MSCOCO 5k测试集RSUM达443.2。
3. 消融实验
- MKG有效性:多模态知识图谱优于仅用文本单模态知识的CVSE方法,验证跨模态隐式知识的价值;
- MGCN有效性:两步推理的MGCN比传统图卷积(CGCN)性能提升显著,RSUM提升3.7%;
- 参数敏感性:实体数300、λc=0.05、MGCN层数1层时性能最优,过多实体/过深网络会引入噪声或过平滑。
4. 定性结果
可视化检索案例证明:MKVSE能通过隐式知识关联,精准检索到文本未直接描述、但语义相关的图像/文本,解决传统模型的检索盲区。
六、结论与未来工作
1. 研究结论
MKVSE通过MKG显式建模隐式多模态关系+MGCN两步图推理,有效解决图像-文本检索中隐式语义关联缺失的问题,在两大基准数据集上取得最优性能,兼具精度与推理效率。
2. 未来工作
- 挖掘更多类型的多模态知识关系,提升模型可解释性;
- 拓展至音频、视频等更多模态,丰富多模态知识图谱;
- 优化图网络结构,解决深层图卷积的过平滑问题。
