0. 论文基础信息
- 标题:Image-Text Embedding Learning via Visual and Textual Semantic Reasoning
- 会议/期刊:IEEE TPAMI 2023
- 核心任务:图像-文本跨模态检索(图文匹配)
- 核心思想:先做视觉/文本语义推理 → 生成全局单一向量 → 简单内积做匹配 → 高精度+超快推理
- 模型:VSRN(基础)、VSRN++(增强版)
1. 研究动机与问题
1.1 现有方法的缺陷
- CNN 全局特征:只做像素级建模,没有物体间语义关系。
- 区域-单词密集匹配(SCAN/BFAN/CAMP/IMRAM):
- 精度高,但推理时要计算所有区域与所有单词的相似度,速度极慢。
- 缺少显式语义推理:无法建模物体交互、空间关系、场景逻辑。
1.2 本文解决思路
不做密集局部匹配,改为:
- 对图像区域:语义关系推理 + 空间关系推理 + 全局语义整合
- 对文本单词:单词关系推理 + 全局语义整合
- 最终图文各一个向量,内积直接算相似度,速度极快。
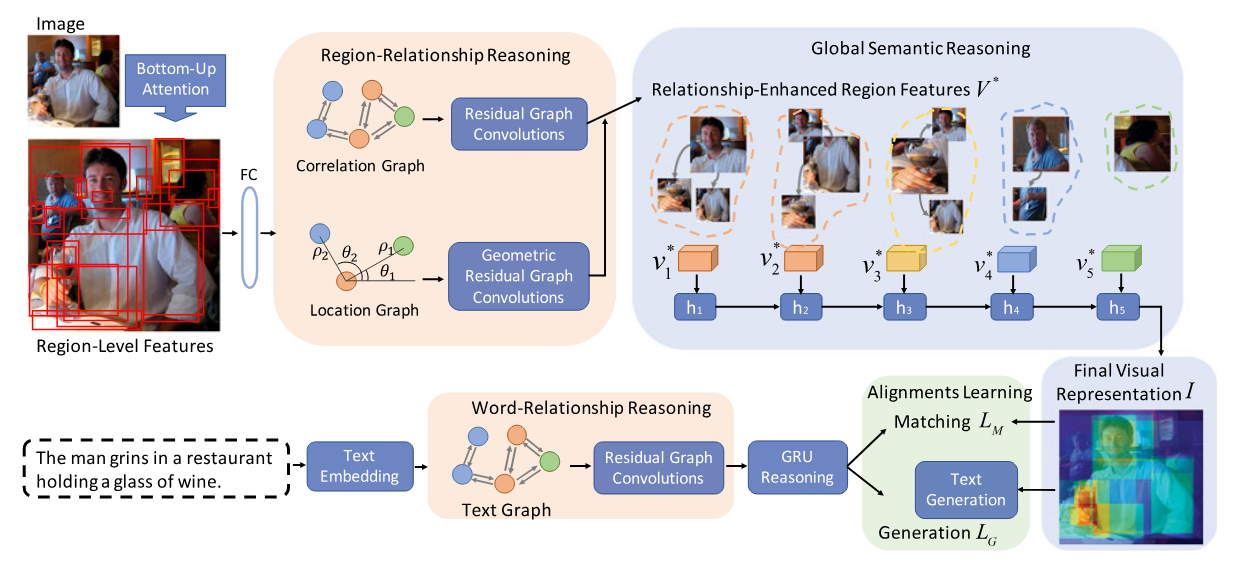
2. 整体模型框架
总流程(图像侧 + 文本侧 + 匹配训练)
图像编码
自底向上区域提取 → 区域语义亲和度计算 → 构建全连接图 → GCN关系推理 → 空间位置推理 → GRU全局语义推理 → 图像全局表征
文本编码
词嵌入/BERT → 单词亲和度计算 → GCN单词关系推理 → GRU全局推理 → 文本全局表征
训练
三元组匹配损失 + 文本生成损失 +(VSRN++:Sinkhorn 归一化)
推理
图像向量与文本向量内积算相似度。
3. 图像端:完整详细计算流程
3.1 自底向上区域特征提取(Bottom-Up Attention)
输入
任意图像
步骤
- 用 Faster R-CNN + ResNet-101 检测器(在 Visual Genome 预训练)。
- 输出:物体/区域类别、属性、置信度。
- NMS 非极大值抑制(IoU=0.7),置信度阈值 0.3。
- 每幅图保留 Top-36 置信度最高的区域。
- 对每个区域取平均池化特征,维度 2048。
- 用线性层映射到统一维度 D:$v_i = W_f f_i + b_f$
- $f_i$:区域原始特征 (2048)
- $W_f$:线性变换权重 (D×2048)
- $v_i$:区域嵌入特征 (D)
- 最终得到区域集合:$ V = {v_1, v_2, …, v_k}, k=36 $
3.2 区域语义亲和度计算 + 全连接图构建(RRR 核心)
目标
衡量两个区域在语义上的相关程度,用于构建图的边权重。
公式(原文严格公式)
两两区域 $v_i$ 与 $v_j$ 的语义亲和度:
$$R(v_i, v_j) = \varphi(v_i)^T \phi(v_j)$$
逐符号解释
- $\varphi(v_i) = W_\varphi v_i$:对 $v_i$ 做线性变换
- $\phi(v_j) = W_\phi v_j$:对 $v_j$ 做线性变换
- $W_\varphi, W_\phi$:可学习权重矩阵 (D×D)
- $R(v_i, v_j)$:余弦相似度类内积,值越大表示语义越相关
图构建
- 节点:所有 36 个图像区域
- 边:由亲和度矩阵 R 完全连接(全连接图)
- 边权重 = $R_{i,j}$
3.3 区域语义关系推理(RRR:Region Relationship Reasoning)
方法:带残差的图卷积 GCN
公式:
$$V^* = (R * W * W_g) W_r + V$$
步骤
- 对亲和度矩阵 R 行归一化(保证数值稳定)。
- 做图卷积(并非卷积):信息在全连接图上传递,每个区域融合其他区域的语义。
- 加残差连接,防止梯度消失。
- 输出:语义关系增强后的区域特征
$$V^{} = {v_1^, v_2^, …, v_k^}$$
每个 $v_i^$ 都包含了*与其他所有区域的语义关联信息。
3.4 区域位置关系推理
目标:建模空间位置关系
步骤
- 计算任意两区域的相对极坐标 $p(i,j)$:
- 包含:距离 + 方向(方位角+仰角)
- 用 M 个可学习高斯核 编码位置信息:
$$v_i^{#} = \left[ \bigcup_{m=1}^M W_m^# \sum_{j\in \mathcal{N}(i)} \kappa_m(p(i,j)) v_j \right] W_r^# + v_i$$ - 残差连接,输出空间增强特征 $V^#$。
- 融合:语义特征 + 空间特征 → 最终关系增强区域特征 $V^*$
$$V^* = \text{L2Norm}(V^* + V^#)$$
3.5 全局语义推理
目标
把 36 个区域特征,融合成 1 个图像全局表征。
结构:门控循环单元 GRU
(1)更新门(控制记忆更新多少)
$$z_i = \sigma_z \left( W_z v_i^* + U_z m_{i-1} + b_z \right)$$
(2)重置门(控制遗忘多少)
$$r_i = \sigma_r \left( W_r v_i^* + U_r m_{i-1} + b_r \right)$$
(3)候选记忆
$$\tilde{m}i = \sigma_m \left( W_m v_i^* + U_m (r_i \circ m{i-1}) + b_m \right)$$
(4)当前记忆(场景表示逐步生成)
$$m_i = (1-z_i) \circ m_{i-1} + z_i \circ \tilde{m}_i$$
最终图像表征
取最后一步的记忆状态:$I = m_k \quad \in \mathbb{R}^D$这是整幅图像的单一全局向量。
区域输入顺序
按检测置信度从高到低输入,效果最优。
4. 文本端
4.1 VSRN 基础版文本编码
- 词嵌入:
$$t_i = W_t w_i + b_t$$ - 用 GRU 编码整个句子,得到句子向量 C。
4.2 VSRN++ 增强版(BERT + 文本关系推理)
步骤
用 12 层 BERT 提取单词特征(固定不微调,省显存)。
单词语义亲和度计算(和图像完全一致)$R’(t_i, t_j) = \varphi’(t_i)^T \phi’(t_j)$
构建单词全连接图,用 GCN 做关系推理:$T^* = (R’ * T * W_g’) W_r’ + T$
用 GRU 做全局语义推理,得到句子全局向量:$C \in \mathbb{R}^D$
5. 匹配与训练(完整损失 + Sinkhorn)
5.1 相似度计算
基础版:直接内积
$$S(I,C) = I^T C$$
5.2 VSRN++:Sinkhorn 归一化
对批次内相似度矩阵 S 做行、列交替归一化,变成双随机矩阵,让匹配更稳定。
$$\mathcal{S}^{(k)’} = \mathcal{S}^{(k-1)} \oslash (\mathcal{S}^{(k-1)} \mathbf{1}\mathbf{1}^\top)$$
$$\mathcal{S}^{(k)} = \mathcal{S}^{(k)’} \oslash (\mathbf{1}\mathbf{1}^\top \mathcal{S}^{(k)’})$$
5.3 匹配损失
$$L_M = \left[\alpha - S(I,C) + S(I,\hat{C})\right]+ + \left[\alpha - S(I,C) + S(\hat{I},C)\right]+$$
- $\hat{C}$:最难负文本
- $\hat{I}$:最难负图像
- $\alpha=0.2$:间隔
5.4 生成损失(Caption 生成正则)
用带注意力的 Seq2Seq LSTM 从区域特征生成 caption:
$$L_G = -\sum_{t=1}^l \log p(y_t | y_{t-1}, V^*; \theta)$$
5.5 总损失
$$L = L_M + L_G$$
- 生成损失只在训练用,推理时移除,不增加耗时。
6. 可解释性
6.1 注意力图
计算最终图像向量 I 与每个区域 $v_i^*$ 的内积,高亮关键区域。
6.2 关系边可视化
展示 GCN 中权重最高的边,模型自动学到:
- 人 ↔ 手 ↔ 飞盘
- 斑马 ↔ 草地 ↔ 水面
- 酒杯 ↔ 嘴
无需任何场景图标注。
7. 优点与局限
优点
- 精度 SOTA
- 推理极快,适合工业检索
- 结构简洁:GCN + GRU
- 可解释
- 训练稳定
局限
- 依赖自底向上区域检测质量
- 未做大规模跨模态预训练(作者列为未来工作)