一、论文基础信息
- 论文标题:KERM: Knowledge Enhanced Reasoning for Vision-and-Language Navigation
- 会议:CVPR 2023(IEEE/CVF Conference on Computer Vision and Pattern Recognition,计算机视觉顶会)
- 发表时间:2023年6月(arXiv预印本:2023年3月28日)
- 作者:Xiangyang Li, Zihan Wang, Jiahao Yang, Yaowei Wang, Shuqiang Jiang
- 单位:
- 中科院智能信息处理重点实验室、计算所
- 中国科学院大学
- 鹏城实验室
- 项目地址:https://github.com/XiangyangLi20/KERM
- 核心领域:Vision-and-Language Navigation(VLN,具身智能·视觉语言导航)
- 核心创新:首次将区域级文本事实知识融入VLN,用提纯-交互-聚合三模块做知识增强推理
二、研究背景与问题
1. 任务定义
VLN:智能体根据自然语言指令,在真实室内3D环境中导航到目标位置,需理解语言、感知视觉、做出动作决策。
2. 现有方法缺陷
- 仅用全局图像特征或物体标签,语义信息不足
- 相似场景/相似物体难以区分,易走错方向
- 未见环境泛化能力差
- 缺乏人类导航时依赖的常识、属性、关系等外部知识
3. 本文核心动机
知识是视觉信息的关键补充,能帮助智能体区分相似候选、提升泛化、增强跨模态对齐。
三、整体方案总览
- 构建知识库:从Visual Genome抽取63万条文本事实(属性对、关系三元组)
- 事实检索:将视图规则切为5个区域,用CLIP做图像-文本向量匹配,每个区域取Top-5事实,共25条fact
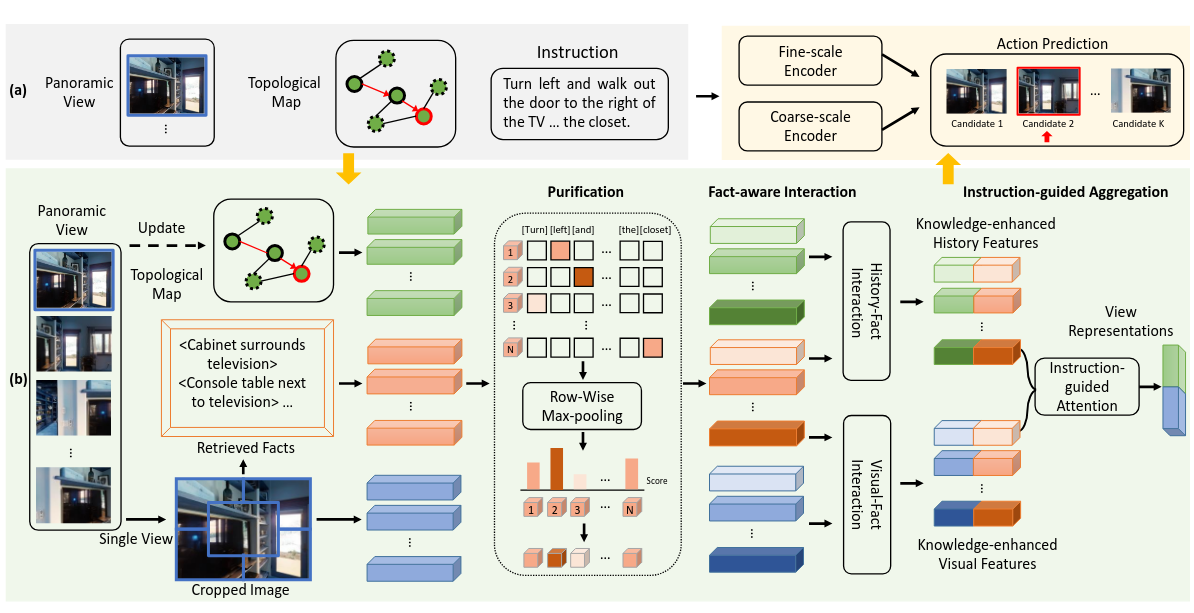
- 知识增强推理(KERM三模块):
- Purification:按指令加权过滤知识、视觉、历史
- Fact-aware Interaction:视觉-知识、历史-知识跨模态融合
- Instruction-guided Aggregation:按指令聚合特征,输出给导航模型
- 导航预测:接入DUET双尺度图Transformer做动作预测
四、技术细节
1. 知识库构建与事实获取
- 来源:Visual Genome数据集
- 事实类型:
- 属性:
(red sofa) - 关系:
(lamp hanging over island)
- 属性:
- 规模:去重后共630K条文本事实
- 检索方式:
- 视图→规则切5块→CLIP图像编码器→图像向量
- 事实→CLIP文本编码器→文本向量库
- 余弦相似度→每个区域Top-5→单视图共25条fact
2. KERM三大核心模块
(1)Purification 提纯模块
- 输入:fact特征Eₙ、视觉区域Rₙ、历史Hₙ、指令L
- 计算fact-instruction相关性矩阵:$A=\frac{(E_n W_1)(L W_2)^T}{\sqrt{d}}$
- 行最大池化得到每条fact权重αₙ:$\alpha_n = \max{A_{n,i}}$
- 加权得到提纯特征:$E_n’ = \alpha_n \odot E_n$
- 视觉、历史做相同提纯
- 作用:弱化无关知识,保留与指令相关的关键信息
(2)Fact-aware Interaction 交互模块
结构:2层跨模态Transformer(CrossAttention + SelfAttention)
视觉-知识交互:
$$\tilde{R}_n = \text{CrossAttn}(R_n’, E_n’)$$$$R_n’’ = \text{SelfAttn}(\tilde{R}_n)$$
历史-知识交互:同结构,得到Hₙ’’
维度:
- Rₙ’:5×d(5个图像区域)
- Eₙ’:25×d(25条fact)
- 输出Rₙ’’:仍5×d
作用:让视觉/历史特征吸收知识语义,实现知识增强
(3)Instruction-guided Aggregation 聚合模块
- 用指令CLS token做注意力,融合5个区域为单一视图向量:
$$\eta_n = \text{softmax}\left(\frac{(R_n W_3)(L_0 W_4)^T}{\sqrt{d}}\right)$$
$$\bar{r}n = \sum{i=1}^5 \eta_{n,i} R_{n,i}’’$$ - 历史特征同理得到ℎ̄ₙ
- 用FFN融合r̄ₙ与ℎ̄ₙ,得到知识增强视图表示
- 作用:形成可直接用于导航决策的紧凑特征
3. 训练策略
- 预训练任务:
- Masked Language Modeling(MLM)
- Masked View Classification(MVC)
- Single-step Action Prediction(SAP)
- Object Grounding(OG)
- 微调:模仿学习+伪交互专家路径监督
五、实验设置
1. 数据集
- REVERIE:高级指令+目标物体定位,路径短
- R2R:分步指令,标准导航
- SOON:长指令+目标物体中心预测
2. 评估指标
- 导航:SR、SPL、NE、TL、OSR
- 物体定位:RGS、RGSPL
3. 基线模型
DUET、VLNBERT、AirBERT、HAMT、HOP等
六、实验结果与结论
- SOTA性能:在REVERIE、R2R、SOON三数据集的可见/未见分割上,多数指标超过之前最优方法
- REVERIE提升最显著:SR↑5.52%、SPL↑6.51%、RGSPL↑4.93%
- 消融实验:
- 提纯、视觉-知识交互、历史-知识交互均有效
- 事实fact效果 > 物体标签object
- 视图切5块效果最优
- 核心结论:
- 外部文本事实可有效补充视觉信息
- 提纯-交互-聚合能高效融合知识
- 知识增强显著提升泛化与区分相似场景能力