Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI
一、基础信息
- 论文标题:Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI
- 发表期刊:IEEE Transactions on Knowledge and Data Engineering (TKDE)
- 期刊评价:CCF A类、中科院1区Top、JCR Q1,数据/知识工程顶刊,学术认可度极高
- 发表时间:2024年11月
- 作者单位:复旦大学、之江实验室、香港科技大学
- 核心标签:具身智能、多模态知识图谱、场景驱动、机器人知识增强
二、论文解决的核心问题
- 通用知识库缺陷:稀疏、粒度粗、缺场景细节、无多模态,不适合机器人
- 大模型参数知识缺陷:幻觉、不可靠、难维护、不可解释、难实时纠错
- 具身智能刚需:机器人需要场景专属、可解释、可纠错、图文结合的外部常识
三、整体思路
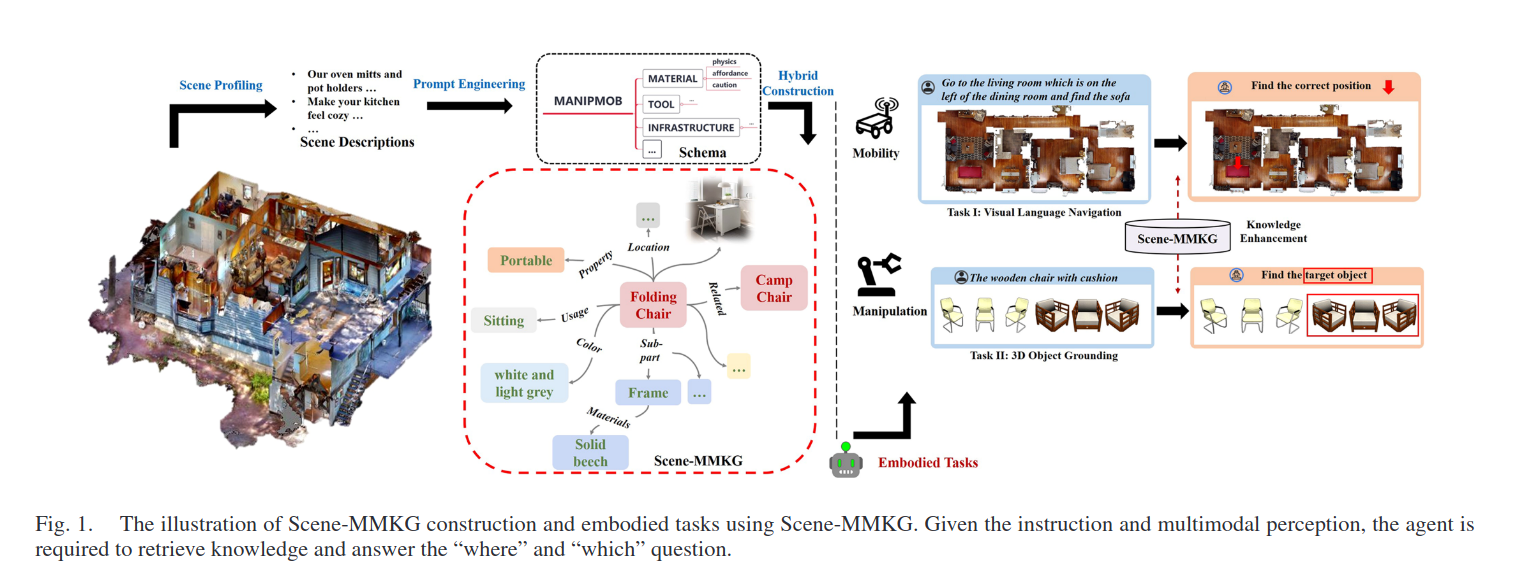
- 提出场景驱动多模态知识图谱(Scene-MMKG):专为机器人定制、单场景聚焦、文本+图像融合
- 构建流程:LLM提示生成Schema → 通用+场景知识填充 → 分层聚合优化
- 落地应用:做机器人版多模态RAG,把图谱注入导航、操作任务,提升决策能力
四、核心方法
1. 基于提示的模式设计
- 输入:场景描述(如“卧室”)
- LLM零样本提取:物体、类别、关系
- 概念扩展+聚类:自动生成场景知识框架
2. Knowledge Population
- 通用知识:从ConceptNet等库自动抽取常识
- 场景专属知识:LLM生成+少量人工校对,补充位置、用法、操作规则
- 多模态:给实体配图(标准图+场景图),同一实体带文本+图像两种信息
3. Quality Control and Refinement
- Hierarchicalization(分层):实体→部件→属性,结构更清晰
- Aggregation(聚合):语义相似属性合并,去冗余、解决长尾
- 全程:算法自动执行,人工仅定规则+校验
五、知识增强模型
核心逻辑 = 机器人多模态RAG
- Scene Knowledge Retrieval(SKR):根据指令/观测检索图谱知识
- Multimodal Denoising:过滤无关图像/文本,保留当前场景有效信息
- Knowledge Encoding:GCN编码,供模型决策使用
两大落地任务
- VLN(视觉语言导航):对应移动能力,靠图谱找路、找目标
- 3D Object Language Grounding:对应操作能力,靠图谱精准识别、定位物体
六、实例与实验
- 实例图谱:ManipMob-MMKG(室内场景,兼顾操作+移动)
- 实验结论:
- 建库成本低、效率高
- 导航SPL、物体定位准确率显著优于通用KG与大模型参数知识
- 多模态 > 单模态,去噪与优化有效
其他文章