MR-MKG
一、基础信息
- 论文标题:Multimodal Reasoning with Multimodal Knowledge Graph (MR-MKG)
- 发表会议:ACL 2024
- 核心任务:多模态问答(ScienceQA)、多模态类比推理(MARS)
- 核心标签:多模态大模型、知识图谱增强、RAG、轻量适配器、跨模态对齐
二、论文解决的问题
- 多模态大模型(LLaVA、BLIP-2等)存在幻觉、知识陈旧/不足
- 传统**文本知识图谱(KG)**只有文字,无视觉信息,无法支撑跨模态推理
- 现有知识增强方案参数大、训练成本高,图文与知识未统一空间
三、整体思路
用外部多模态知识图谱(MMKG)提供图文知识 → 检索相关子图 → 编码为向量 → 对齐到LLM文本空间 → 拼接输入LLM推理 → 用跨模态对齐优化效果
轻量、无全量微调、解决幻觉、提升多模态推理精度
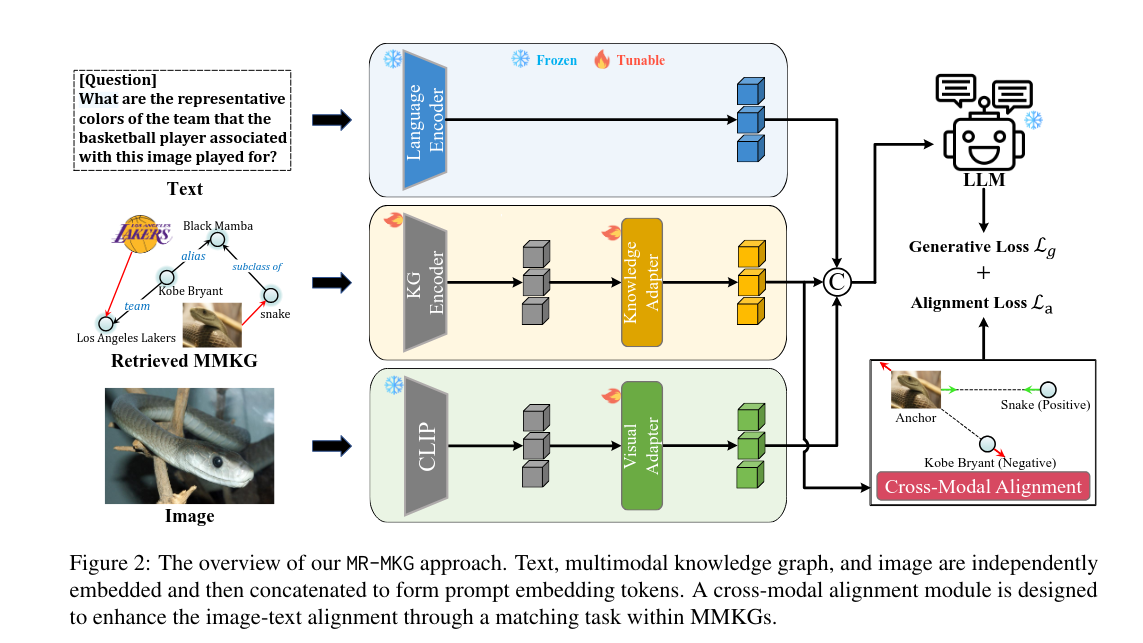
四、方法总流程
- 分别编码
- 文本(问题)→ 语言编码器 → 文本向量
- 图片 → 视觉编码器 → 图片向量
- MMKG子图 → RGAT(一种GNN)图编码器 → 知识向量
- 适配器对齐
- 图片向量 → 视觉适配器 → 文本空间
- 知识向量 → 知识适配器 → 文本空间
- 拼接输入LLM
- 文本向量 + 对齐后图片向量 + 对齐后知识向量 → 送入LLM
- 跨模态对齐训练
- 在MMKG内部做:图片实体 ↔ 文本实体匹配
- 用Triplet Loss拉近对应、拉远不对应,让三者空间统一
五、模型详细结构
1. Language Encoder
- 直接用LLM的词嵌入层(FLAN-T5/LLaMA-2)
- 全程冻结
2. Visual Encoder
- 用CLIP的ViT
- 输出图片特征 → 经线性层+单头注意力 → 适配文本空间
- 全程冻结
3. KG Encoder
- 输入:从MMKG检索的相关子图(Top10~20三元组)
- 模型:RGAT(关系图注意力网络)
- 作用:把图结构(实体+关系+图片)编码成知识节点向量
4. Knowledge Adapter + Visual Adapter
- 两个小线性层+注意力
- 作用:把图片、知识向量映射到LLM词嵌入空间
- 仅训练这部分,参数极小(≈LLM的2.25%)
5. Cross-Modal Alignment
- 任务:MMKG中随机选图片实体,匹配对应文本实体
- 损失:Triplet Loss(三元组损失)
- 目标:让图文知识在同一空间,减少歧义、提升匹配精度
六、训练方式
- 两阶段训练
- 预训练:在MMKG-grounded数据集上学基础图文知识
- 微调:在ScienceQA/MARS上做任务微调
- 损失函数
- 生成损失Lg:LLM正常回答损失
- 对齐损失La:跨模态匹配损失
- 总损失:L = Lg + λLa
- 核心特点
- 冻结LLM + 冻结视觉编码器
- 仅训练适配器、RGAT、对齐层 → 超轻量、低成本
七、关键要点
- 不是全图输入,每次只取相关小子图(≈10条三元组)
- 不是输入字符串,是拼接向量直接进LLM嵌入层
- 本质是多模态知识增强RAG,但用结构化MMKG而非文本库
- 创新不在发明算法,而在:
- 首次将MMKG内部图文实体对齐用于LLM多模态推理
- 超轻量参数训练仍达到SOTA
八、核心效果
- ScienceQA:超过LLaVA、MM-CoT等SOTA,平均精度↑1.95%
- MARS:Hits@1↑10.4%
- 仅训练≈2.25% LLM参数,训练成本极低